이번에도 역시나 표준이 아닌 이야기..
(표준 이야기도 어서 끝을 내야 하는데..)
올 하반기를 강타(?)하고 있는 개인정보보호 이슈와.. 최근 몇년 간 시대의 대유행인 인공지능을 결합한 federated learning 이야기를 해 볼까 한다.. (원래 내 논문 이야기는 거의 안 하는데.. 이건 좀 해야 할 듯. 다른 연구자들과의 협력이 필수라..)
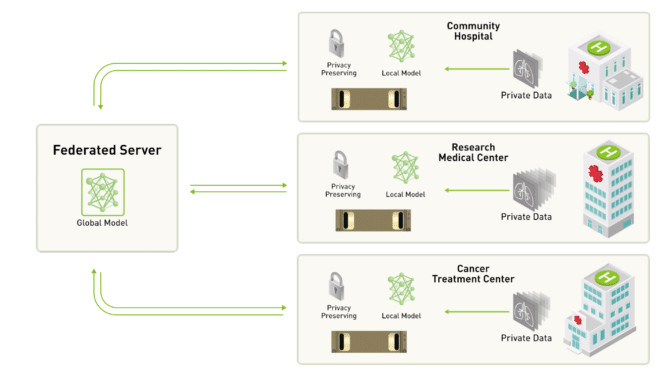
이제 유명해져서 아는 사람은 다 아는 federated learning..
특히 개인정보 보호가 큰 이슈가 되는 헬스케어 데이터 분석에서 중요한 기술이라고 말이 많은 federated learning..
(개인적으로 몇년 전부터 이런 기술을 도입해서 사용해야 한다고 강력히 주장하기도 했고.. 특히 가명처리의 대안으로 적극 주장 )
근/데/ 논문이든 뭐든 말만 하지 실제로 하는 사람은 의외로 많지 않은 federated learning.. (국외 포함. 나도 이 논문 전에는 말만 하던 사람)
솔직히 말만 많지, 하는 사람이 많이 없어서 그냥 시작했다..
잠깐 잡설.. 근데 내 연구 주제의 대부분이..
내 생각엔 너무 필요한데 하는 사람이 별로 없어서 내가 하는 거…
전형적인 답답한 놈이 우물파는 연구..
그러다 보니 요즘엔 많은 연구자들이 으쌰으쌰하는 연구는 반쯤은 의도적으로도 회피 중.. 레드오션에서 같이 박터지게 싸우고 싶은 생각은 없음..
참고로 내가 하기 싫은 연구는 사짜들이 사기치는 분야가 많은 연구..
말도 안되는 주장으로 중요하다고 사기치면서 혹세무민하는 무리가 판치는 동네는 쳐다도 보기 싫은데.. 요즘 그런 바닥이 없다는 게 문제..
원래 하던 연구인 경우에는 사짜들 입닥치게 하려고 사기치는 분야 위주로…
그런데 그러다보니 너무 피곤해서.. 신규 진출은 절대 안하는 중 (ex. DTx 등)
본론으로 들어와서
Federated Learning.
한국에선 주로 연합학습 이라고 번역 중
Federated learning의 개념과 원리에 대해서는 개념을 처음 제안한 구글에서 만든 이 만화가 제일 좋은 듯 하다.
(심지어 Domain까지.. https://federated.withgoogle.com/ )

아주 간단히 요약하면
데이터를 한 곳에 집적시키지 않고, 분산된 형태에서 데이터 분석을 수행
(추가 상세한 federated learning의 개념은 참고할 만한 자료가 많으니 알아서들 잘 찾아서 보시길.. 뭐 그리 어려운 개념도 아니고.. 구현 상 아주 복잡한 것도 아니라서..
이미 나도 여러번 소개했고)
Google에서 처음 federated learning을 제안하게 된 건..
아무리 서버가 많은 Google이라도 (심지어 2012년에 Google: We’re One of the World’s Largest Hardware Makers 라는 기사도.. ) 막대한 연산량에 부담을 느끼게 되었고, Android OS를 사용하는 수많은 device들을 이용해 보자는 어찌보면 당연한 생각(?!)을 하게 되었다..
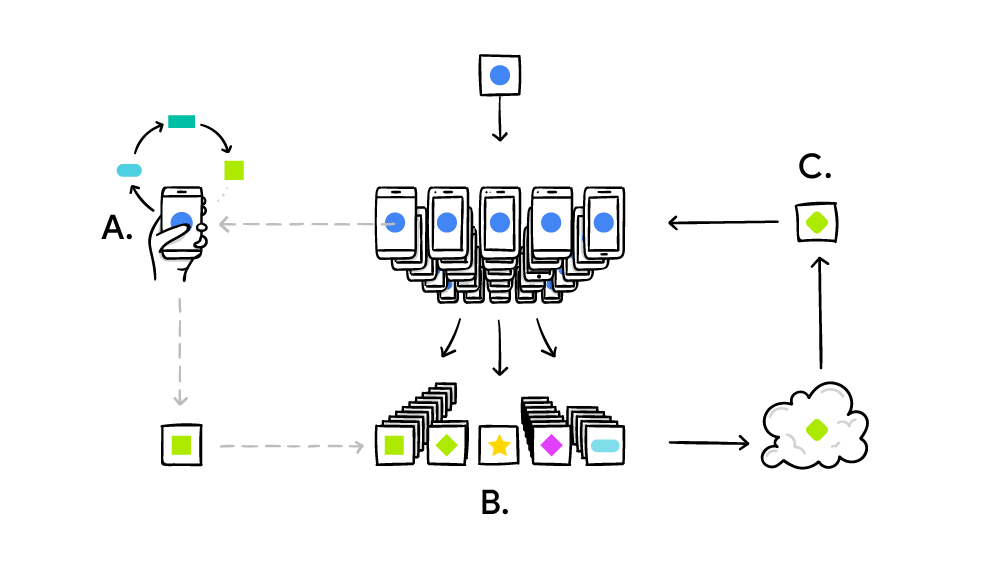
그래서, device가 충전 중인 idle 타임에 필요 연산을 하고, 중앙에서 이를 갱신하는 형식,,
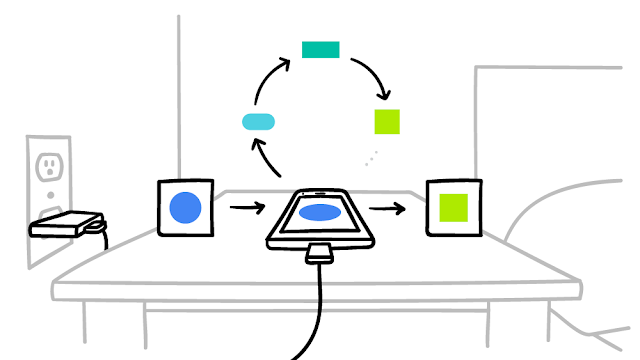
(출처:https://ai.googleblog.com/2017/04/federated-learning-collaborative.html)
즉, 원래는 resource 활용 효율화를 위해서 제안된 개념인데..
데이터를 한 곳에 집적(accumulation)시키지 않으니,
- 데이터가 집적되지 않으니 집적된 저장소에 대한 해킹 공격의 위험도 줄어들고
- 가명정보인 경우 데이터 집적으로 인해 생기는 재식별 위험도 줄어들고
데이터가 아닌 모델의 파라미터만 주고 받으니
- 연구자가 데이터를 직접 보지 않아 개인정보 보호는 더 잘 되고
여러가지 개인정보 보호와 관련된 장점이 생기게 된 것이다! Bingo!
특히 헬스케어 데이터로 오니
- 데이터 반출의 시비가 없고
라는 장점이 더 추가되어.. 더욱 좋은 기술이 되었다.

의료 데이터에 쓰면 좋다는 논문은 진짜 많은데..
실제로 검증한 논문은 거의 없다.
Federated learning이 필요하다고 중요하다고 말로 푸는 논문들은 진짜 많은데..
그 논문 많은 arXiv에도 실제 결과가 있는 논문은 없다..
(좀 나쁘게 말하면 이빨만 깐다.. 당황스러웠다. 저 개념이 나온지 몇년이 되었고.. 이 바닥의 추세라면 이미 단물.. 다 빨아먹어야 하는데..)
실제로 데이터를 가지고 결과를 보여주는 논문들은 이 정도..
- Multi-Institutional Deep Learning Modeling Without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation. http://europepmc.org/article/MED/31231720
MICCAI (Medical Image Computing and Computer Assisted Interventions) 2018 Brain Lesion WorkshopWorkshop 논문으로 헬스케어 데이터로 실제 결과 보여준 (내가 아는 한) 최초의 논문 - Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data https://www.nature.com/articles/s41598-020-69250-1
- Federated Learning of Electronic Health Records Improves Mortality Prediction in Patients Hospitalized with COVID-19 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7430624/
- Predicting Adverse Drug Reactions on Distributed Health Data using Federated Learning https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7153050/
심지어 Open source도 예상외로 없다..
- TensorFlow Federated (TFF): https://www.tensorflow.org/federated
- OpenMined PySyft: https://github.com/OpenMined/PySyft
- FATE (Federated AI Technology Enabler): https://github.com/FederatedAI/FATE
정도.. (찾으면 좀 더 나오는데.. 실제 제대로 working하는 건 별로 없… )
그리고, 더 큰 문제는 open source 들이 대부분 client-server 혹은 다른 방식의 실제 network 상에서의 동작을 고려하여 구현된 것들이 아니라 single server에서 FL을 흉내내는 형태로 구현된 거라는 상황..
(즉, 이빨만 까는 논문들과 차이가 없이 그냥 흉내만 내는 )
상용으로 가면
(하나 더 있었던 것 같은데.. 기억이 안 나서 찾을 수가.. ;;)
그래서 결론: (없으니) 직접 하자
물론 내가 만든 건 아니고 학생이…
목적은
- 실제 헬스케어 데이터에서 동작하는지 검증
- 실제 network 환경에서 동작하는지 검증
이게 초안
- Reliability and Performance Assessment of Federated Learning on Clinical Benchmark Data
https://arxiv.org/abs/2005.11756
최종 출판논문..
- Lee GH, Shin SY, Federated Learning on Clinical Benchmark Data: Performance Assessment, J Med Internet Res 2020;22(10):e20891
https://www.jmir.org/2020/10/e20891- (무려 Appendix만 14개.. ㅎㅎ;)

논문의 코드는 여기..
(맘대로 쓰시고 피드백 부탁)
논문에 대해서 설명을 하자면..
- 위에서 이야기한 것처럼 성능에 대해서 Reference 할 수 있는 논문이 극히 부족함..
따라서, 기존 방식으로 학습한 결과와 Federated learning 결과를 비교해야 함.
그래서 잘 알려진 헬스케어 benchmark data를 이용하기로 결정 - 기존 결과는 SOTA 논문 결과로!
다만 SOTA 논문 중 source code가 공개되어 있는 결과로.. SOTA를 달성한 source code로 돌려야지 공평한 비교가.. - 코드 구현 시 client-server로 구현을 하는데.. 원래 Google의 의도와 달리
의료 기관들이 참여해서 학습할 때는 초기 참여 기관이 학습 과정에 모두 참여한다고 가정해도 무방함. 디바이스를 가정할 때처럼 어떤 디바이스가 학습 과정에 참여할 지 고민할 필요가 없음 - 실제 네트워크 환경을 위해 AWS를 사용했고, 전부 network communication으로 구현
그런데 그냥 유명한 benchmark인 MIMIC-III 같은 걸로 해 보니 잘 되더라. 큰 재미가 없잖아..
그래서, 현실을 고려한 몇 가지 가정을 더 추가했다.
(왜냐하면 현실을 항상 막장.. 무엇을 상상하든 그 이상..)
결과가 아주 잘 알려져 있고, 이것저것 해 보기 좋아서
우선 MNIST 가지고 시작
MNIST가 0 ~ 9 숫자 10개로 구성되었다는 점을 고려해..
AWS상에 10개의 client와 1개의 server로 구성.
전부 별도의 node로 구성해서 실제 network traffic 발생시킴
- (Basic FL) 각 client에 10개의 숫자가 이쁘게 동일한 size로 분포
- 각 client는 random하게 고른 숫자를 600개씩 가지고 있음.
- data 전체는 6000개

- (Imbalanced FL) 각 client에 10개의 숫자가 서로 다른 size로 분포
- 각 client는 random하게 고른 숫자를 서로 다른 갯수로 가지고 있음
- 다만 data 전체는 6000개로 동일하게 유지

- (Skewed FL) 각 client는 하나의 숫자만 가짐
- client 1은 숫자 0만 가지고, client 2는 숫자 1만 가지는 식..
- 각 client는 하나의 숫자를 600개씩 가짐
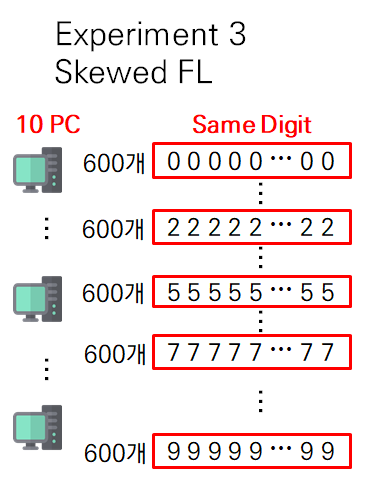
- (Imbalanced & Skewed FL) 각 client가 하나의 숫자만 가지고 서로 다른 size로 분포
- 즉 case 2+ case 3
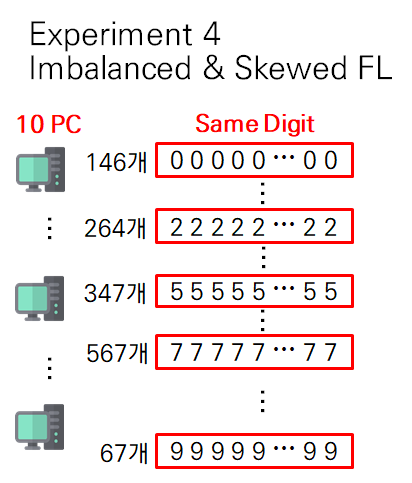
이런 setting으로 실험을 해 봤다..
일반적인 방법 (데이터를 전부 다 모아서 하는 거)까지 추가해서 성능을 비교해 보면
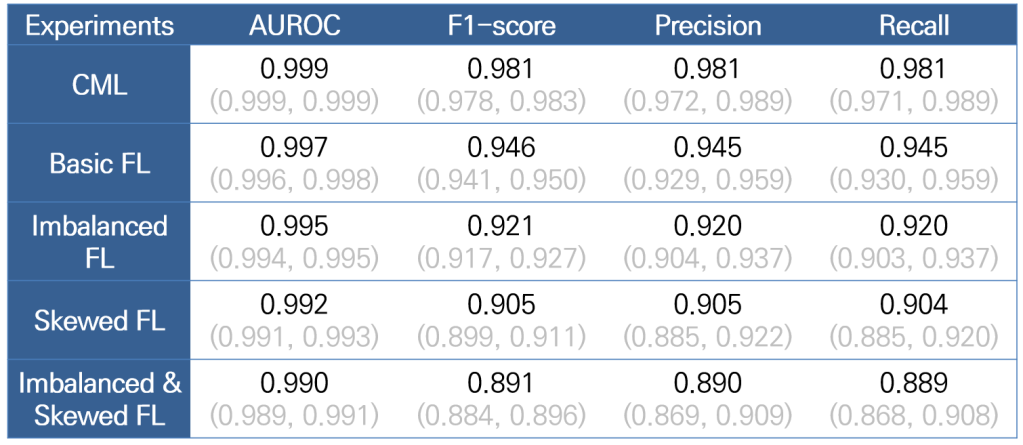
놀랍게도 성능 차이가 거의 안 난다..
가장 극한의 상황(솔직히 현실에서도 일어나기엔 너무 심한 가정인)을 가정한 경우에도 AUROC가 불과 0.009차이난다… F1은 0.09정도 차이나고..
(뭔가 대박의 냄새가 솔솔 나기 시작했다..)
저것만 보면 안 믿을까봐.. confusion matrix도 appendix에 추가해 뒀다. (직접 저 위 논문 링크에서 찾아봐라. 일일이 달아주기 귀찮다)
Source code도 Github에 공개했으니.. 그래도 의심되면 직접 돌려봐라..
MNIST가 너무 쉬워서 그런 거 아니냐.. 그럴 수 있다.
그리고 헬스케어 데이터도 아니다..
그럼 헬스케어 데이터로 해 보자.
제일 유명한 MIMIC-III로.
최대한 객관성을 유지하기 위해서 SOTA (State-Of-The-Art, 한국말로 최고성능) 성능이면서 source code가 공개되어 있는 task를 찾았다.
그래서 결국 찾은 게
“In-Hospital mortality classification” (REF)
다만 이번엔 data class가 어떻게 구분되는지 (숫자 0 ~ 9처럼) 명확하지 않고..
MIMIC dataset에 해당 data의 출처(어느 병원에서 가지고 온 건지)가 명시되어 있지 않아서.. 위의 setting에서 case 1, case 2만 진행했다
- (Basic FL) 계산 시간 상의 이슈로 (AWS 요금…;;;;; 이 연구.. 연구비 같은 거 없이 순수히 재미로 한 거다..) client는 3개로 (즉, 병원 3개가 참여한다는 가정).
전체 데이터를 중복없이 3개로 똑같이 배분 (1/3씩) - (Imbalanced FL) client 3개에 전체 데이터를 중복없이 배분한 건 같은데, 50%, 30%, 20%로 배분
즉, case 2가 일반적인 상황을 가정한 거다..
(병원마다 환자 수가 달라서 전체 n수가 다른 상황)
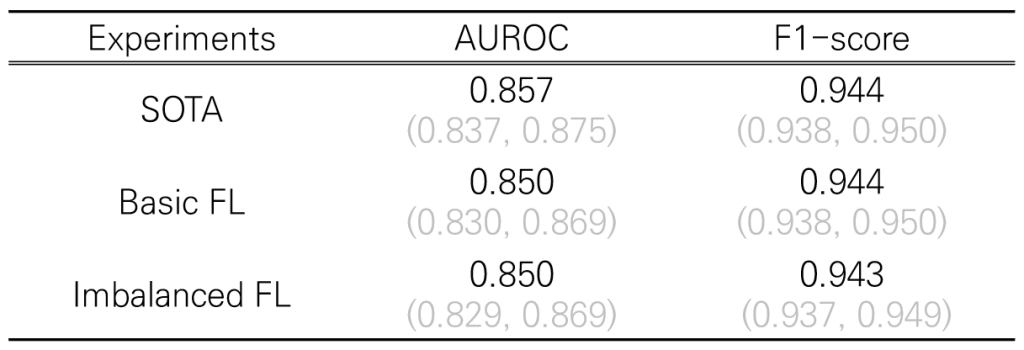
역시나 성능 차이가 거의 없다. Imbalanced상황에서..
(confusion matrix는 역시 appendix로 제공)
이 때 확신했다. 이거 물건이다..
헬스케어 데이터 하나 더 추가 (리뷰어 요청 사항 -_-;)
Physionet ECG 데이터. [REF]
SOTA가 있는 source code 찾으면서 느낀건데.. paperwithcode.com처럼 훌륭한 사이트 덕에 찾기 쉬워지긴 했는데.. 실제로 돌려보면 안 돌아가는 게 많음.
환경 설정의 문제가 아니라 그냥 안 돌아감 -_-; ㅎㅎ;;
그래서, 객관적 비교 대상 찾기 힘들었음..
왜냐하면 저자가 SOTA 성능을 낸 source code를 federated learning frame으로 변경해서 돌려야지 공정한 비교가 가능했기 때문에..
알다시피 이 놈의 딥러닝.. 성능의 공정한 비교가 참 … 쉽지 않다. 그래서 최소한 동일한 코드로 테스트하려고 했다.
(참고로 federated learning은 하나의 conceptual framework라고 봐야 할 듯. 그래서 실제 학습하는 모델은 뭐든 가능)
Source code가 실행 가능한 녀석들을 찾아야 했는데.. 하아.. 왜 재현성 문제가 생긴다고 하는지 해 보면 암… 안 돌아가 -_-
실험 세팅은 MIMIC-III와 동일하게 함.

역시나 AUROC, F1모두 0.01 정도 차이남.
마지막 소감.
“이거 대박이다”
당연히 성능 저하가 어느 정도 있을 것이라고 예상하고, 그 성능 저하를 어느 정도까지 용인하냐가 고민이었는데.. 성능 저하 거의 없음.
결국 개인정보 보호라는 장점을 취하면서 성능 저하라는 단점은 충분히 무시할만한 수준. Wow!
그래서, 앞으로 우리 Lab은 federated learning을 한 축으로 가지고 가기로 결정.
여러가지 이론적인 부분에서도 이것저것 해 볼게 많음. (weight update방법 및 network topology 관련..)
특히나 90년대 후반 ~ 2000년대 초반에 정립된 parallel 혹은 distributed programming 개념들을 도입하면.. 성능 및 속도 향상도 꽤 기대해 볼 수 있을 듯.
(참고로 이 논문에서는 속도는 전혀 측정하지 않았음.. 추후엔 속도도 고려해야..)
역시 해봐야 아는 게 많음.
이렇게 말은 많은데 실제 결과가 없는 주제들이 상당수 있음..
그 중 하나는 내년 연구 주제로 선정..
(똥인지 된장인지 꼭 먹어봐야 아는 건 아니지만.. 안 먹어보고 소설 쓰는 건 그만하자..
뭔지는 arXiv에 공개 이후..)
이건 조금 이론스럽게 갈 예정.. 원래 박사과정때는 뭔가 이론적으로 있어빌러티한 연구가 좋거든.. 충분히 이해하고.. 필요도 하고.. 결과도 궁금하고.. 실제로 가능한지
그런데 federated learning 관련해서 명심해야 하는 거..
- 외부와의 통신을 위해 network port는 하나 열려야 한다.
- 이것도 쉽지많은 않다. 보안 심사 대상
- 각 기관의 데이터는 전부 같은 형태로 정리되어야 한다.
- 데이터 표준화 이슈.
- FL이 아니라 FL 할아버지가 와도… 해결 못함. FL은 데이터를 모으지만 않을 뿐이지 데이터 표준화 및 정리는 반드시 필요
- 여전히 security 이슈는 존재한다. 데이터를 중앙에 집적해서 발생하는 문제점만 해결
Federated Learning관련 추후 연구로는 (여전히 아직까지 실제 데이터로 한 연구가 부족하여)
다시 한번 기존 방법(한군데 모아서 AI로 분석)으로 한 결과가 있는 실제 임상 데이터로 국내 모 병원과 작업 중.. (같은 컨소시엄이라 데이터를 동일한 형태로 정리했고, AI 성능 평가를 위해 검증 완료)
결과 나오면 바로 논문 작성 예정. (이런 저런 사정으로 예상보다 딜레이 중. 전부 내 쪽 사정 -_-;)
저 논문까지 나오면 그걸 기반으로 앞으론 이제 그냥 Federated Learning only로 할 꺼임. 굳이 centralized해서 비교/분석할 이유 없을 것으로 보임 (남들도 하고 있겠지..)
현재 국외 모 병원과 이야기 중..
국/내외 병원 연구자 분들 관심 있으시면 언제든지 연락을..
ps.
답답한 놈이 우물판다 시즌 2로
Privacy Preserving Data Mining을 위해서 각광받고 있는 동형암호(Homomorphic Encryption)도 SDS 연구소 보안팀이랑 해 봤다.
SDS에서 만든 Solution을 SDS에서 평가한 거고.. 난 그냥 IRB만 받아준 정도
(그래서 연구비 안 받고 했다. 다들 양심은 지키자..
리베이트성 연구는 하지 말자..)
이것도 논문 나오면 글로..

언급하신 MICCAI 워크숍 논문보다 헬스케어 분야에서 더 먼저 출판된 논문들이 생각보다 많이 있습니다.
Federated Tensor Factorization for Computational Phenotyping; 2017 KDD
(https://dl.acm.org/doi/pdf/10.1145/3097983.3098118)
SAFETY: Secure gwAs in Federated Environment Through a hYbrid solution with Intel SGX and Homomorphic Encryption; 2017 arxiv -> 2018 IEEE/ACM trans. on computational biology and bioinformatics
(https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8345622)
Privacy-preserving patient similarity learning in a federated environment; 2018 JMIR
(https://pubmed.ncbi.nlm.nih.gov/29653917/)
2019년도 IMIR 연감(yearbook)에서 AI in healthcare TOP3 논문으로 선정된 논문입니다.
참고하시라고 남기고 갑니다^^
좋아요좋아요
오.. 감사합니다.
좋아요좋아요
federated learning 개념이 뭔지 궁금해서 들어왔는데 실제 연구사례랑 같이 볼 수 있어서 너무 좋았습니다. 종종 들르겠습니다~
좋아요좋아요
너무 유익했습니다 ㅎㅎ 감사합니다.
좋아요좋아요
좋은 정보 감사합니다 교수님~
좋아요좋아요
궁금했는데 자세히 설명해주셔서 감사합니다 🙂
좋아요좋아요
잘 보고 갑니다
좋아요좋아요
오호… 그냥 한 번 구글에서 검색해 봤는데, 구글이 신수용님 글을 첫번째로 띄워 주세요. 반갑습니다. 잘 봤습니다.
글을 읽는데 자꾸 얼굴이 떠올라 동영상을 보는 줄 … ㅎ
좋아요좋아요
ㅎㅎ;; 개인적으로 아는 사람들은 음성지원 된다고 ^^
좋아요좋아요