Healthcare Data? Data! Data!!
2. Clinical Data: Data in EMR
이제 본격적으로 각 data의 종류에 대한 이야기를 할 꺼다.
그런데, 뭐 논문 찾아보면 나오는 이야기는 할 생각이 없고.. 그런 건 review 논문 찾아봐라. 나도 그런 거 쓸꺼면 블로그에 안 쓰고 survey paper 써서 저널에 낼 꺼다. 굳이 내가 블로그에 그런 걸 쓸 이유는 없다. 내가 쓰고 싶은 건 (논문으로 쓸 수 없는) 한국의 현실이다.
헬스케어 AI에 관심이 급격히 증가하고 있는데…
현재 한국의 healthcare data 현황을 내가 아는 한 공유해서..
연구자들에게는 정말 이 분야를 연구해도 될지 알려주고자 하는 의도도 있고..
의사들한테 사기치는 사기꾼 업체들을 걸러내기 위한 의도도 있다. (솔직히 사짜들이 너무 많다..)
이 번 글의 제목을 clinical data로 할까 Data in EMR로 할까 고민을 좀 했다. (뭐가 다르냐고 할 수도 있지만.. -_-) 절충안으로 Clinical Data: Data in EMR 이라고 부제 비슷하게 달았다. (EMR에 대해서 좀 하고 싶은 말이 많아서..)
단순하게 clinical data라고 했지만.. 여기엔 너무나도 많은 데이터가 있다. 당장 생각나는 것만 해도.. “진단, 투약, 각종 검사(혈액, 영상, 병리… ) 결과, 수술, 입원, 외래, 응급.. ” 너무나도 다양한 spectrum의 여러 데이터가 있다. 이걸 하나의 표나 그림으로 나타내기에는 정말 힘든 일이다. (나중에 여유가 되면 한번 시도해 볼지도.. )
일단.. 여러 데이터 중에서 의료 영상(CT/MR, 초음파, 내시경 등등등)은 전문분야가 아니라서 pass~. 이 쪽 데이터는 이미 기업체들도 잘 알고, 영상의학과 교수님들이 있으신데다가.. 딥러닝이 뜨면서 많이 적용되어서 난 그냥 가만히 있는 걸로 ..
몇 가지만 이야기하자면.
- 국내 데이터 구하기는 힘들지만.. 외국 데이터는 많이 open되어 있다. 내가 아는 대표적인 것들이
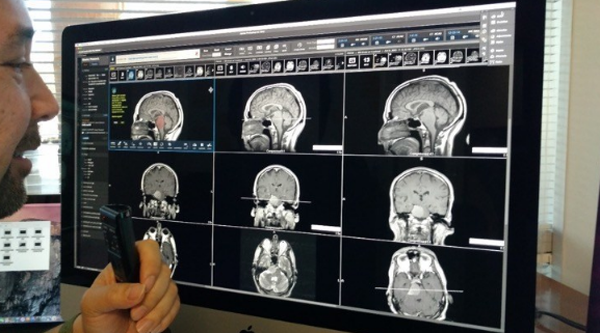
- 의료영상은 기본적으로 PACS (Picture Archiving and Communication System)에 저장되고, CT/MR 같은 still image는 DICOM (Digital Imaging and Communications in Medicine) 표준을 따른다.
즉, 제품화하고 싶으면.. PACS에 연동되는게 좋고, 결국 DICOM에 대해서도 공부하는 게 좋다. (기/승/전/표준~ 결국 이 쪽은 돌고 돌아서 데이터는 표준으로 귀결.. ^^;)
또 한가지 이야기해야 하는 건.. 의료 영상도 영상의학과 쪽은 잘 되어 있는데.. 병리는 … 갈 길이 멀다는 것이다. Digital Pathology가 있긴 한데.. 국내 도입은 그리 많지 않은 걸로 알고 있다. (첨 들었을 때가 거의 10년 전인데.. 요 몇년 간은 나도 잘 몰라서.. )
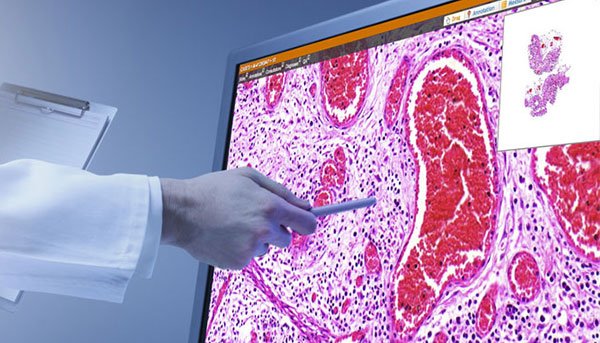
역시, 이 쪽도 잘 아는 분야가 아니라서 PASS!.
근데, 병리쪽이 IT와 관련해서 할 게 진짜 많다. Digital Pathology부터 시작해서, 보고서 구조화, 입력 편의 향상 (voice 2 text 등)… 근데 다들 논문쓰기 좋은 유전체에만 관심을…
(뒤에서 다시 이야기할지 모르겠으나.. 국내 Health IT가 이상하게 되고 있는 건..
이 걸로 논문을 쓰기 쉽지 않다는 것도 한 몫을 한다.
교수가 시간쓰고 돈 써서 뭔가를 했으면 얻는 게 있어야 하는데.. 논문이 잘 안 나오거든..
유전체처럼 한방이 있는 것도 아니고..
ETRI 전종홍 박사님이 적절한 비유를 하셨는데.. 다들 스포트라이트를 받는 공격수만 하고 싶어하는 것 같음~ )
영상은 이정도로 pass하고..
이제 다른 데이터들을 생각해 보자.
해당 데이터들은 우리 나라의 경우 EMR혹은 OCS (Order Communication System)에 저장된다. (우리 나라 병원정보시스템을 이상하게 만든 첫번째 원흉이 OCS라고 보는데.. 이건 주제가 벗어나니 나중에 생각나면 이야기하기로 하고 )
물론, 아직 종이 차트 쓰는 곳 있다. (설마 slip은 없겠지?) 그리고 그걸 scan해서 영상EMR이라고 주장한다. -_-; 꽤 여러 병원들이 이 상황인데.. 돈이 없다보니 궁여지책이라는 거 잘 알고 있다. 근데, 이 상태라면 BIG DATA, AI.. 이딴 이야기하지 마라. 그냥 쪽팔려 해라…. (이러다 학교에서 짤릴 지도 -_-)
가장 중요한 DATA도 제대로 관리를 못하면서 무슨..
기지도 못하면서 날려고 하는 거다.
내 블로그니 일단 내 맘대로 쓰고 싶은 말을 쓰다보니..
기대와 다를 수도 있겠지만
이번 글의 주제는 “국내 EMR의 냉정한 현실과 개선 방안” 이다.
의외로 의료진들도 현실을 잘 모르고 (아는 분들은 잘 아시지만..) 이제 의료 분야에 관심을 가지는 연구자들은 들으면 황당할지도.. (냉정한 자아비판만이 개선의 첫걸음이다.)
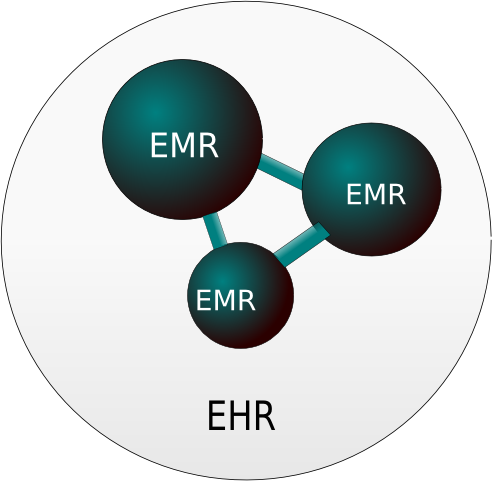
전자의무기록(Electronic Medical Record, EMR 혹은 Electronic Health Record, EHR).. 참 할 말이 많다. (국내 병원정보시스템은 참 할 말이 많다.. 솔직히 대한병원정보협회 분들이 나보다 훨씬 많이 알고 하고 싶은 말도 많을텐데.. 그 분들은 입장이 있다보니.. 병원에서 IT업무를 하는 사람들의 모임이라.. )
우선 뭐 궁금해 하는 분이 있을지 몰라서.. EMR과 EHR의 차이는 아래 그림처럼, EMR이 서로 연동되어서 정보를 주고 받으면 EHR이라고 보면 된다. 근데 이제는 큰 차이 없어 막 쓴다. (나도 이젠 굳이 구분안하고 쓴다) 진료정보교류가 필수이다 보니..
자 냉정하게 국내 EMR의 현실을 보자~
Fact 1: 제대로 된 EMR을 쓰는 곳은 많지 않다.
한국에서 거의 사실처럼 알려져 있는 EMR과 관련된 헛소문이 뭐냐 하면..
국내 EMR 보급율이 엄청나게 높다는 거다.
정/말/일/까?
당연히 통계다. (궁금하면 링크를 클릭해서 첫 줄만 봐라.)
저 숫자는 심평원에서 만든 “국내 의료기관의 표준화된 전자의무기록시스템(EMR/EHR) 도입지원 방안” (2015.12)에 나오는 숫자이다. 심평원 사이트에서도 보고서를 찾을 수가 없고.. 기사만 몇 개 나오는데.. 해당 보고서의 표 하나를 발췌하자면 아래와 같다.
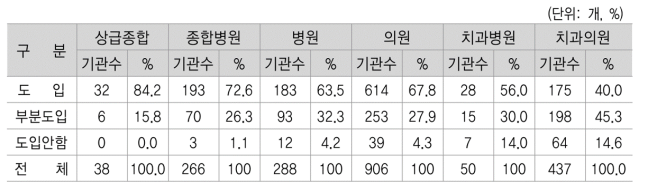
부분도입까지 포함해서 얼핏보면 90%가 맞는 것처럼 보인다.. (오.. 대단한 한국!) 앞에서 말한 것처럼 통계의 장난이다. (이것도 국뽕이다..).
일단, 전산화 = EMR 도입이 아니다. OCS만 써도 전산화한건데?
둘째, 부분도입은 말장난이다. (OCS에 기록창 몇 개 있는 걸 EMR이라고 우기는 거다)
도입도 보면.. comprehensive EMR이 아니라.. 미국 기준으로는 부분 EMR인데.. 도입이라고 우기는 거다. 심지어 영상 EMR도 EMR로 인정해 준다. (지금 장난치냐?)
박래웅 교수님이 IJMI (International Journal of Medical Informatics)에 최근에 발표한 논문을 보면 2015년 조사 결과 우리나라 3차 의료기관에서 comprehensive EMR 도입율은 불과 11.6%이다.
11.6%!
basic EMR도 불과 46.5%이다.
합쳐봐야 58.1%.
학문적 기준으로 조사한 이 논문의 숫자가 더 정확하다고 보이며.. 개인적으로도 이 숫자가 더 현실성있는 숫자라고 생각한다. 참고로 comprehensive EMR과 basic EMR의 차이는 아래 표와 같다.
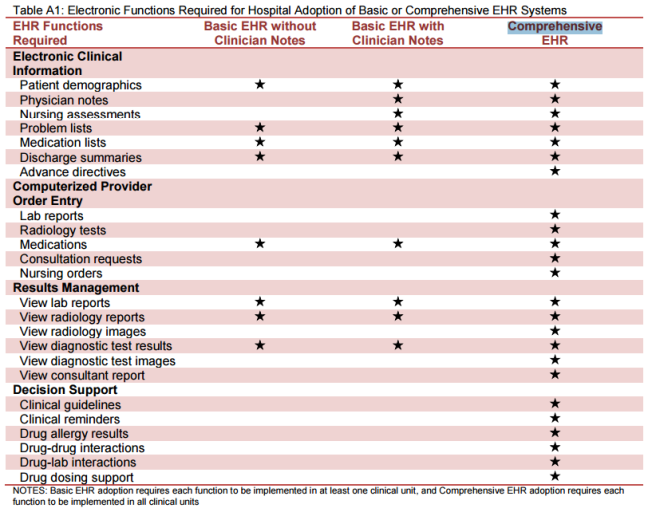
Electronic Functions Required for Hospital Adoption of Basic or Comprehensive EHR Systems. ONC Data Brief, No. 23, April 2015
심평원의 숫자는 OCS가 포함된 허수가 엄청나게 많다.. 현실을 왜곡하니 개선이 안 된다.
그러니, 사기치지 말고
제대로 된 EMR부터 도입해라.
Big 5과 그 아래 병원들과의 차이는 엄청나다.. 분당서울대병원 EMR이 잘 나간다고.. 우리나라 의료기관 EMR이 전부 다 잘 나가는 거 아니다.
Fact 2: 우리나라 EMR은 Word processor다.
황당하겠지만 사실이다.
2000년대 초반 대형병원에 정보화 바람이 불 때.. 이 때 병원들의 최우선 목표가 무엇이었냐 하면 “4less hospital”이었다. 4Less.. paperless, chartless, slipless, filmless. 종이없고, 차트없고, 슬립없고, 필름없는 병원이었다.
우리나라 EMR은 (솔직히 우리나라 현실상 EMR이랑 OCS랑 구분하는게 좀 웃기긴 하다만.. 어쨋든) chartless를 위해서 만들어진 시스템이다. (OCS는 slipless, PACS는 filmless, paperless는 기타 다른 정보시스템들이. 병원 정보시스템.. 진짜 복잡한 시스템이다. ) 손으로 쓰던 chart를 없애는 가장 빠르고 편한 방법이 뭐였을까? word processor를 만드는 거다.
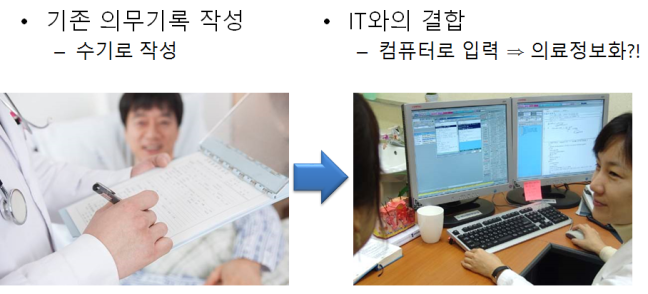
그냥 손으로 쓰던 걸 타이핑하는 거다. 그 이상도.. 그 이하도 아니다. 그럼 이 시스템은 잘못 만들어진 건가? NEVER. 사용자의 요구에 아주 잘 부합한 시스템을 만들어 준 거다. 갑이 원하는 대로.. 지금 의료진들의 불만은 본인들이 워드를 만들어 달라고 해 놓고는 엑셀 기능이 없다고 투덜대는 거다. 엑셀이 필요하면 엑셀을 달라고 했어야지.. (안 되는 건 안 되는 거다)
어쨋든 이게 지금 워드 프로세서이다 보니.. 자유도가 너무 높다. 그래서 현실은..
- 대부분 text
- 수없이 많은 약어: 심지어 같은 약어인데 진료과마다 (더 나가서 의사마다) 다른 뜻으로 씀
이러니 검색도 힘들고.. 재활용은 더 힘들다.
또 다른 문제는
- data가 100% 정확하지 않다는 것이다.
미국 eMERGE 컨소시움에서 2011년에 발표한 논문을 보면 몸무게가 1000 kg인 사람, 성인인데 키가 15cm인 사람 등등.. 많은 오류가 발견된 것을 소개하고 있다. 우리 나라라고 다르지 않다. 내가 아는 사례만 해도 비일비재하다.. (이건 서로 민망하니 밝히지 않도록 하고.. ) 앞에서 말한 논문의 Table 3을 소개하면 다음과 같다.
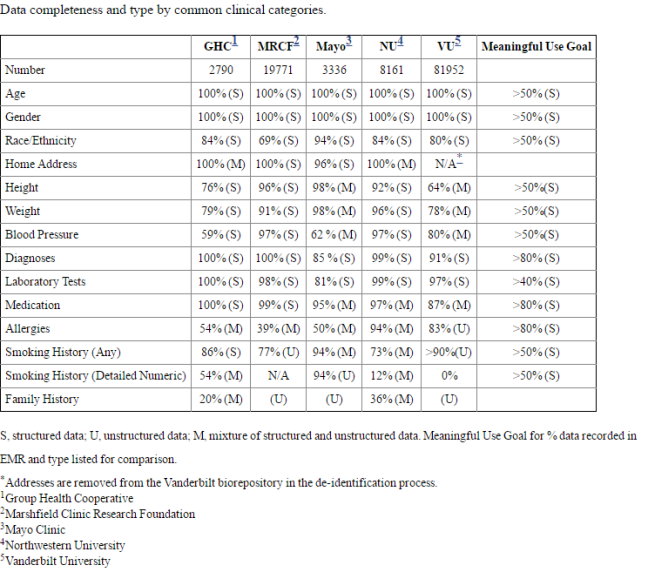
이런 상항에 있는 clinical data를 한마디로 요약해 주는 사진과 twit.
사진은 VUNO 정규환 박사님 페북 posting에서 가져옴.

의료정보학 대가인 UCSF Atul Butte 교수의 재밌는 Tweet.
제대로 된 EMR도 없으면서.. 있어봐야 그냥 word processor 쓰고 있으면서..
무슨 big data고 AI타령인지..
자 현실은 시궁창이지만.. 나름 열심히 하시는 분들도 있고.. 제대로 된 시스템을 만드는 회사도 있다. 그래서 앞으로는 제대로 된 EMR을 쓰는 병원이 많아질 것으로 본다.
그럼 EMR에 있는 내용을 제대로 활용하기 위해서는 어떻게 해야 할까?
SOLUTION 1: 의무기록 구조화
WORD가 아닌 EXCEL 기능이 지원되는 EMR을 위해서, 가장 중요한 것은
“의무기록 구조화”
라고 본다. 한 마디로 의무기록 구조화라고 했지만.. 많은 걸 내포하고 있다.
Excel에서 여러명이 동시에 값을 채우기 위한 table을 만든다고 생각해 보라. 그럼 서로 필요한 항목을 정의하고, 각 항목에 어떤 값을 넣어야 하는지 약속을 할 것이다. 이 과정이 거창하게 말하면 “표준화“하는 것이다. 항목을 표준화하고 해당 항목값을 숫자로 할지, 코드화할지 정하면 된다.
결국 healthcare data는 돌고 돌아서 “표준”으로 귀결된다. 내가 ISO와 HL7 활동을 하는 이유가 이것이다. 잘 모르던 시절.. 그냥 데이터 모아서 분석이란 걸 하려고 봤더니.. 데이터를 정리하는데 기준이 필요했고.. 남들이 쓰는 기준을 찾다보니 표준을 보게 되었다. 그리고 나중엔 여러 기관 데이터를 합치려고 하다 보니 또 표준이 필요해 졌다.
물론 나처럼 표준까지 안 봐도 된다. 나야 일을 하다 보니 결국 표준을 보게 된 거지만.. 표준 몰라도 분석하는 데 큰 지장은 없다. 나같은 사람이 정리만 해 주면.. 하지만정리해 줄 사람이 없으면… 그냥 표준 공부해라. 방법이 없다.
다시 의무기록 구조화로 돌아와서..
구조화를 하는 방법엔 참 여러가지가 있다.
- 한국에서 만든 CCM (Clinical Contents Model)
- 유럽의 ISO 13606
- Cleveland Clinic에서 만든 DCM (Detailed Clinical Model)
- ….
좀 자세한 게 궁금하면 관련 과제 보고서 를 보면 된다. (내가 하는 과제다.. 무지하게 길다 ^^; 근데 앞 쪽 일부만 보면 된다.. 분량만 긴 보고서라.. 다만 내가 이 과제를 한다고 해서 이 분야 전문가라는 편견은 가지지 말아 달라.. 나도 잘 모른다 -_-; 정말 어쩔 수 없는 상황들이 겹쳐서 내가 하는 것일 뿐…. 나보다 전문가가 너무 많다. )
저 보고서를 보기도 힘들다면.. 그냥 CIMI (Clinical Information Modeling Initiative)만 기억해라. 다양한 기존 방식을 그냥 다 통합하겠다는 목표로 시작된 이니셔티브다. CIMI 만세~ (너무 진도가 느리긴 하지만)
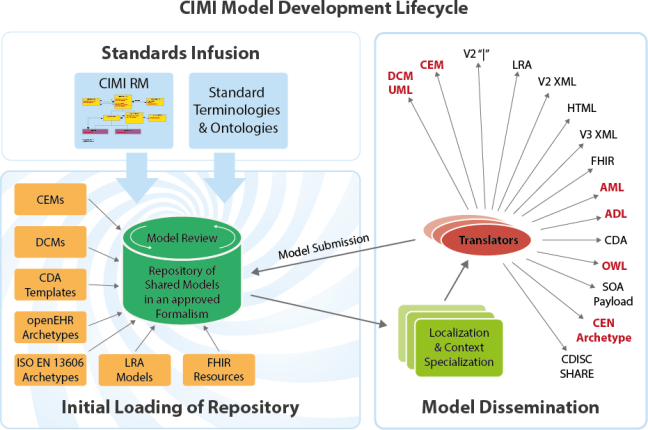
그냥 그것도 귀찮으면..
의무기록구조화: 여러 명이서 사용할 표를 만들기 위해서 필요한 항목을 정의하고, 각 항목에 어떤 값을 넣는지 약속하는 것
만 기억해라.
이렇게 구조화화면 데이터가 표준화되고, 오류가 사전에 예방될 수 있다. 즉,
- 용어 사용의 모호성/중의성 해결
- 같은 용어를 진료과마다 다른 의미로 사용하는 것 예방
- 같은 질병을 기관마다 다양하게 표현하더라도 통합 가능
- 컴퓨터 처리가 가능한 명확한 해석 기준 제공
- 데이터 입력 오류 방지
가 가능해 진다. 예를 들면 다음 Tweet을 참고해라.. CDE는 NIH에서 만든 common data element이다.
SOLUTION 2: 자연언어처리
방금 이야기한 의무기록 구조화는 이제 앞으로 입력할 데이터에 관한 것이다.. 근데 이미 10년 넘게 text로 기록한 자료들이 있다. 이걸 무조건 살려야 한다.
Text에 심폐소생술을 가해서 정보화하려면 어떻게 해야 할까? 당연히 이 분야를 좀 해 본 사람이라면 나올 대답이 자연언어처리 (Natural Language Processing) 이다.

외국에선 clinical NLP 많이 한다. 리뷰 논문도 많고.. (pubmed 검색해 봐라. 엄청 나온다) 하나만 추천하자면 세계의료정보학회(IMIA)에서 매년 발행하는 IMIA Yearbook에 나온 “Clinical Natural Language Processing in 2015: Leveraging the Variety of Texts of Clinical Interest”. (솔직히 나도 읽어보진 않았지만.. Yearbook에 나온 리뷰들은 일단 믿고 볼만하다. 그리고 이 글을 쓰는 시점에서 Clinical NLP review 논문 의뢰를 받았다. open access 저널이니 나중에 출판되면 link를 걸겠다)
학술 논문 외에도 많은 competition들이 있었는데.. 가장 대박이 Heritage Provider Network에서 진행한 3백만 달러 상금의 대회. (결국 최종적으로 1등에게 50만 달러를 줬다. 현재 Heritage Health Prize 2.0을 Kaggle에서 진행 중이다.) 어쨋든.. 3백만 달러를 상금으로 걸었다는 것은 3백만 달러만큼의 가치가 있으니 하는 것 아니겠는가..
이 외에 생각나는 것만도 TREC medical record track, i2b2 challenge 등.. 수도 없이 많았다.

자.. 그럼 한국에서는? 개인적인 의견은 NO다. 될 수 있는 이유보다 안 되는 이유가 너무 많아서..
안 되는 이유 몇가지를 들어보면
- 통일되지 않은 약어: 컴퓨터 이해 불가
- 전문 의학 용어: 많은 knowledge 필요
- 한글 의무 기록의 특성: phrase (구문) not sentence (문장)
- 영어와 한글이 혼합된 text: 심지어 기호도 있다 -_-;
- 쓸만한 한국어 NLP tool 부재: ETRI는 Exobrain 결과물을 공개하라!!
내가 볼 때 가장 큰 문제는 phrase not sentence 다. 내 개인적인 경험도 그렇고..
약어나 전문 의학 용어 문제는 시간만 투자하면 극복은 가능하다.. 영어랑 한글이 혼합된 것도 어차피 한국어 NLP tool이 잘 만들어지면 해결 가능한 문제고..
이 놈의 의무기록들이 전부 조각조각난 형태다.. tagging, parsing을 해봐야 쓸만한 정보가 안 나온다.. 그래서 결국 내가 취한 방법은 Regular expression. 보다 상세한 설명은 이 논문을 봐라. 서울아산병원 ABLE의 익명화 방법을 만들 때 사용했던 모든 노가다가 설명되어 있다. 왜 있어보이는 NLP 기법을 안 쓰고 단순무식한 regular expression을 썼는지.. (리뷰어가 따지고 들어서 참 구질구질하게 설명했었다. 솔직히 이게 한국어가 아니었으면.. 훨씬 좋은 저널에 갔을 거라고 자부한다) 그러고 보니 이전에 설명을 하긴 했다.
그리고, 일부 검사보고서(주로 병리보고서)들은 Semi-structure다. 심한 경우 띄어쓰기, 들여쓰기까지 약속된 형태다. 그러니 패턴만 알면 99% 정도의 정확도로 data 추출이 가능하다. 예전에 썼던 포스터의 예제를 보여주자면 다음 그림과 같다. 아주 잘 된다. (근데 이런 거 해 보고 의무기록 text 처리할 수 있다고 사기치는 업체들이 있다. 우리 이런 구라치지는 말고 살자…)
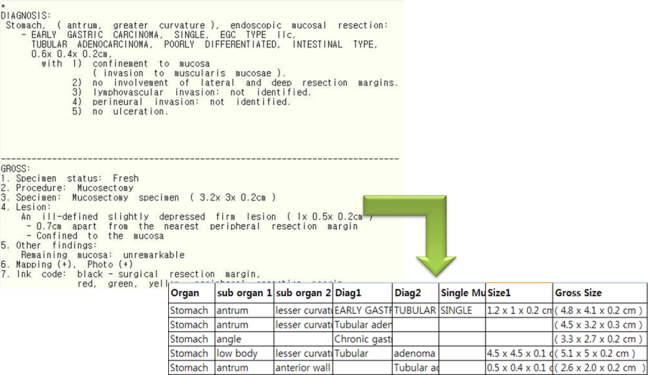
요약하자면.. 일단 regular expression으로 시작하면 급한 불은 일단 끌 수 있다! 바로 시작하자. 그러면서 제대로 된 NLP 연구자를 찾으면 된다.. (한국에 잘 없다는 게 함정. 찾더라도 그 사람이 의료에 관심이 있을 꺼라는 기대를 하지 마라..-_- 그런 귀인을 만나면.. 잘 모셔야 한다.) 그리고 장기적으로 연구를 해야 한다.
단, 여기의 걸림돌은 의료진의 높은 기대치이다.. 분석은 다 하고 아직도 논문으로 못 쓰고 있는 게 하나 있는데.. (아.. 이거 빨리 털어야 하는데..) 요구했던 거 precision을 무조건 95% 이상으로 해 달라고 해서.. 정말 노가다 끝에.. 맞췄다. 당연히 regular expression으로. 이유는 앞에서 계속 이야기했고.. 알다시피 precision에 집중하면 당연히 recall은 떨어진다. (이게 뭔 소리인지 모르겠으면.. 따로 공부해라. 그냥 이 두개가 trade-off관계다.) 대략 62% 대.. 별로 맘에 안 들어서 둘다 적절하게 맞춘게.. precision 90% 초반, recall이 80% 후반.. (대충 기억에 의존한 숫자. 찾아보기 귀찮다) 꽤 성공적인 결과였다. 근데 최종적으로 요구받은 건 Precision > 95% & Recall > 90% . 그냥 접었었다. 이제 논문이 아쉬우니 다시 잘 살려봐야 겠다 -_-;
SOLUTION 3: Phenotyping
또 하나의 큰 문제는 진단명이 부정확하다는 거다. 보통 환자들이 질환을 하나만 가지지는 않고, 여러 개의 질환을 동시에 가지고 있는 경우가 많다. 근데 그걸 일일이 입력하자니 시간도 부족하고 해서 제대로 정리를 안 한다.. POMR (Problem-Oriented Medical Record) 선호하는 시니어 교수님들이 많으신데.. 현실적으로 불가능하다보니.. (근데 정말 제대로 POMR 방식으로 의무기록이 입력되면 이런 문제 없을텐데.. )
대부분의 경우 보험 청구를 위한 진단명 코드 하나만 넣고 땡~ 이다. 나중에 변경도 잘 안 한다. 결국 환자의 이력을 전부 살펴봐야 정확한 판단이 되는 거다. (시간 부족으로 인한 더 심각한 시간 부족을 야기한다..)
이처럼 환자들의 진단명이 제대로 되어 있지 않다는 건 전세계가 비슷한 상황이라고 하고.. 앞에서 소개한 eMERGE에서 또다른 훌륭한 project를 진행했다. 이름하여 PheKB
PheKB: a knowledgebase for discovering phenotypes from EMRs
EMR 내용을 분석하여 빠진 진단명을 채우는 프로젝트이다. 예를 들면 아래 그림을 봐라. Type II Diabetes 환자를 추가하는 예이다.
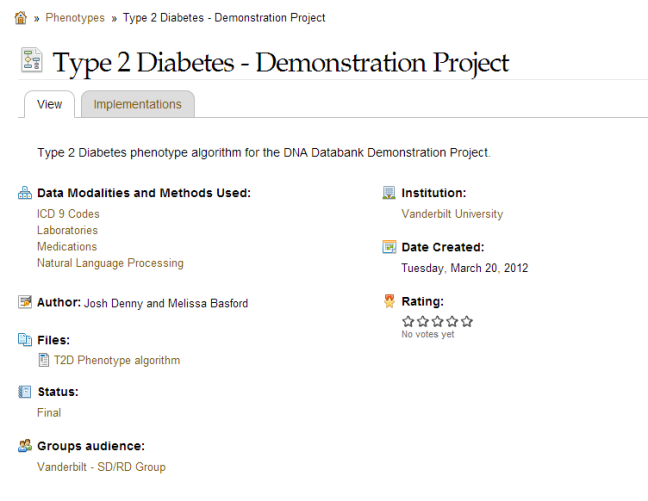
Files에 있는 word 파일을 보면 당뇨병 환자를 찾기 위한 방법이 상세히 기술되어 있다.
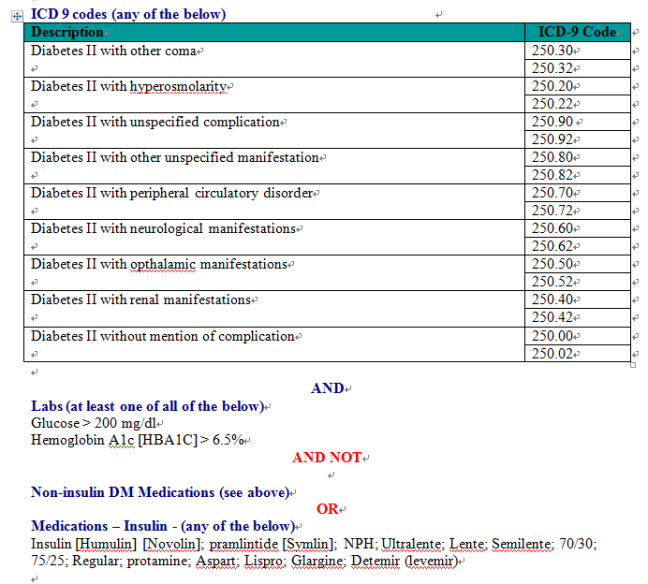
뭐 이미 우리나라의 경우도 역학하시는 분들은 수도 없이 해 본 내용이다. (소위 말하는 조작적 정의…) 다만 그걸 공유하지 않는다는 게 문제인데.. 우리도 그냥 web site하나 만들어서 공유하자… 뭘 그렇게 남들이 훔쳐갈까봐 걱정하는지 모르겠다. 그냥 서로 공개하고 돕고 살자..
이와 유사하게 유사진단을 하나로 합칠 때 어디까지 합칠 것이냐가 좀 애매한 문제인데.. 역시나 미국에서 좋은 tool을 제공하고 있다. Clinical Classification Software (CCS) for ICD-10 by Agency for Healthcare Research and Quality
Excel 파일이니.. 그냥 보고 쓰면 된다.
대충만 정리해도 이 정도다..
근데 뭐 big data solution만 도입하면 다 된다고 생각하지는 않겠지?
지금도 그렇게 생각한다면.. 니 맘대로 하세요. 이게 똥이라고 아무리 이야기해도 직접 똥인지 된장인지 굳이 먹어보겠다면..
지금 병원들이 급한 건 뽀대나는 analytical solution 도입이 아니라,
EMR/OCS 개선을 통한 data 정제작업이다.
근데, 이건 폼도 안 나고.. 성과도 단기간에 안 나고.. 나도 이거 했지만.. 논문도 못 쓰고..
하지만 외면할 수는 없다.
정말 그런데 분석은 해 보고 싶다면..
Open되어 있는 외국 clinical data set을 써라.
GitHub에 아주 잘 정리된 게 있다. 여기서 적당한 거 찾아 써라.
Medical Data for Machine Learning

“Healthcare Data? Data! Data!! (2) – Clinical Data: Data in EMR”에 대한 답글 12개